Revealing Occlusions with 4D Neural Fields
1Columbia University
2Toyota Research Institute
Summary
We introduce the task of dynamic scene completion: Given a monocular video as input, our model produces a 4D representation that captures the entire scene content along with all the static and dynamic objects within it over time. Secondly, in order to train and benchmark learning-based systems for object permanence, we contribute two large-scale synthetic datasets with rich annotations. Thirdly, we propose a framework that integrates transformer mechanisms within a spatiotemporal neural field for densely predicting scene features, and demonstrate that it exhibits occlusion reasoning capabilities. Our representation is conditioned on both local and global context via cross-attention, allowing it to generalize across different scenes.
Example on GREATER
Click here to view more long-term mesh visualizations for our model trained on the GREATER dataset.
Click here to view short-term visualizations that specifically focus on occlusion scenarios, primarily involving the yellow snitch.
Example on CARLA-4D
Click here to view more long-term mesh visualizations for our model trained on the CARLA-4D dataset.
Click here to view short-term visualizations that specifically focus on occlusion scenarios involving pedestrians, cars, and motorcycles.
Method
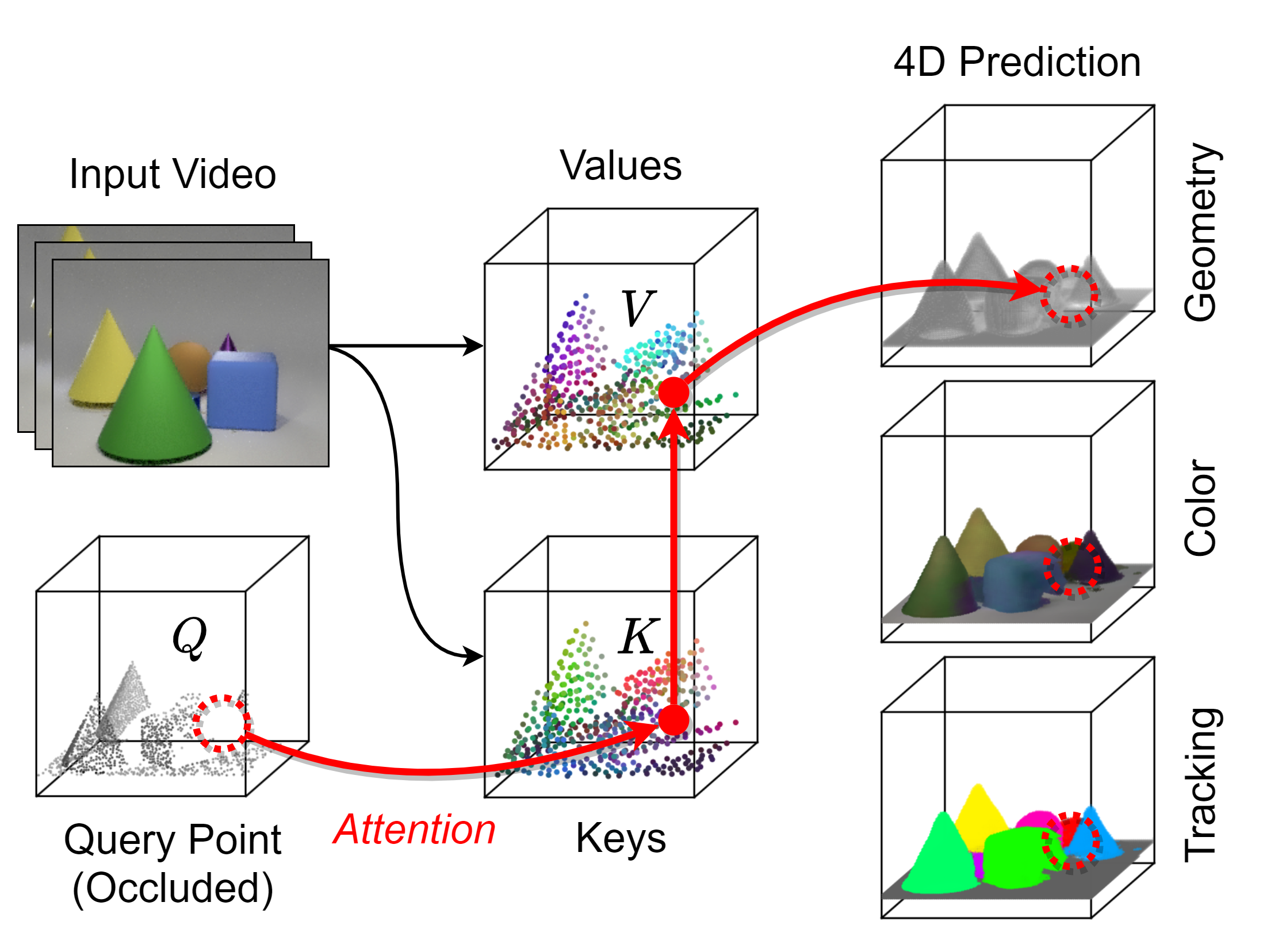
Supervision
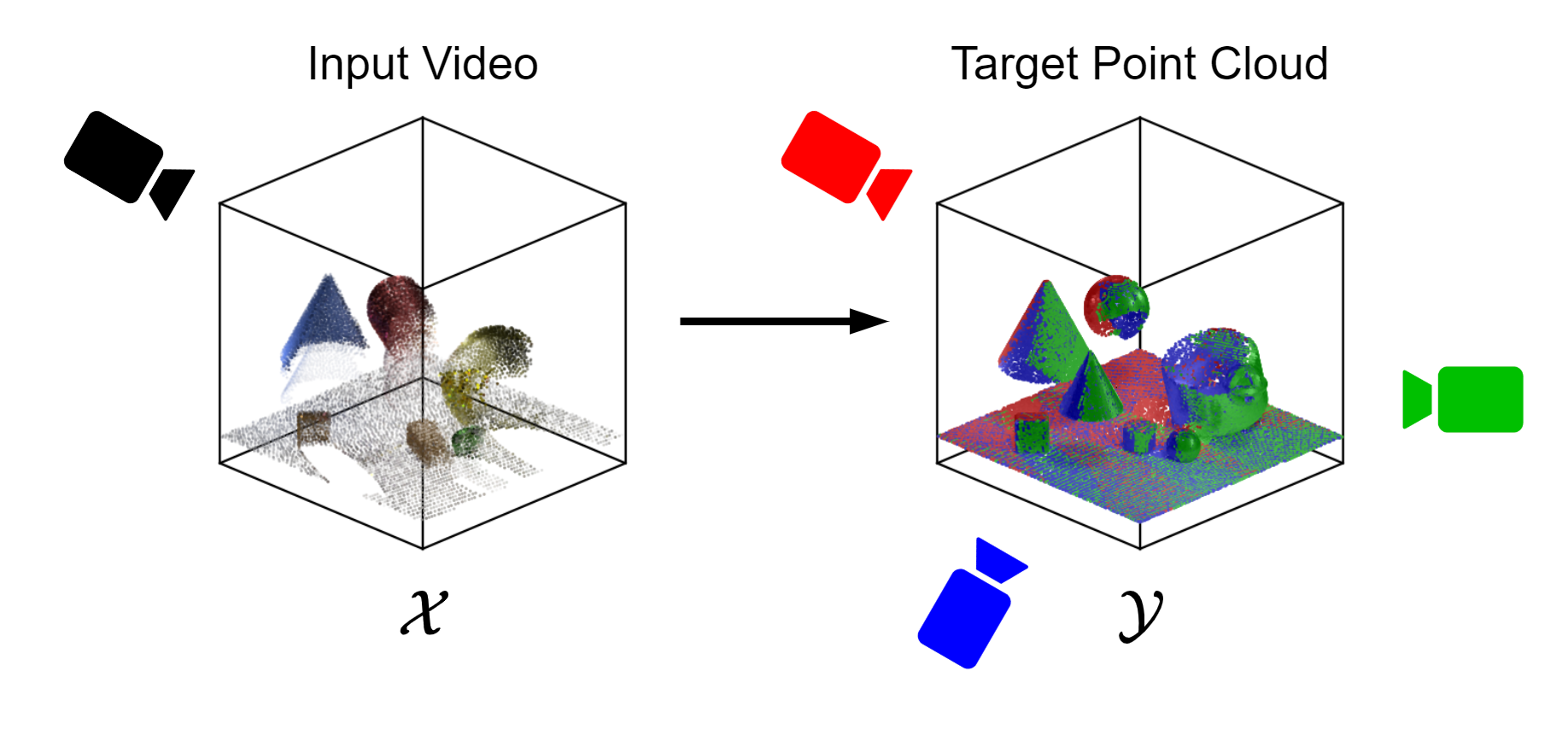
Datasets
We contribute two multi-view RGB-D datasets:
- GREATER is based on CATER, and each scene contains up to a dozen cubes, cones, cylinders and spheres that move around, occluding one another in random ways. We capture 7,000 scenes lasting 12 seconds each, with data captured from 3 random views spaced at least 45° apart horizontally.
- CARLA-4D is created with a realistic driving simulator from which we record scenes covering a wide variety of different towns, vehicles, pedestrians, traffic scenarios, and weather conditions. We sample 500 scenes lasting 100 seconds each, with data captured from 4 fixed views (forward, left, right, top).
Please see this Google Form link to request access to both datasets, or this repository to view the underlying generation code.
Paper

Abstract
For computer vision systems to operate in dynamic situations, they need to be able to represent and reason about object permanence. We introduce a framework for learning to estimate 4D visual representations from monocular RGB-D, which is able to persist objects, even once they become obstructed by occlusions. Unlike traditional video representations, we encode point clouds into a continuous representation, which permits the model to attend across the spatiotemporal context to resolve occlusions. On two large video datasets that we release along with this paper, our experiments show that the representation is able to successfully reveal occlusions for several tasks, without any architectural changes. Visualizations show that the attention mechanism automatically learns to follow occluded objects. Since our approach can be trained end-to-end and is easily adaptable, we believe it will be useful for handling occlusions in many video understanding tasks.BibTeX Citation
@inproceedings{vanhoorick2022revealing,
title={Revealing Occlusions with 4D Neural Fields},
author={Van Hoorick, Basile and Tendulkar, Purva and Sur\'is, D\'idac and Park, Dennis and Stent, Simon and Vondrick, Carl},
journal={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2022}
}
Video Presentation
Acknowledgements
This research is based on work supported by Toyota Research Institute, the NSF CAREER Award #2046910, and the DARPA MCS program under Federal Agreement No. N660011924032. DS is supported by the Microsoft PhD Fellowship. The views and conclusions contained herein are those of the authors and should not be interpreted as necessarily representing the official policies, either expressed or implied, of the sponsors. The webpage template was inspired by this project page.